
Learning Unsupervised Representations for Sensing Humans with mmWave Radars
Supervised by Prof. Amirali Aghazadeh
mmWave radar data is rich in information related to humans like pose and movement. We also observe that collection of data is easy, however labelling the data is extremely hard owing to the fact that this data is not directly human interpretable unlike images and videos. In this project, we have built an unsupervised framework to extract spatial and temporal features of the data which are critical to downstream supervised tasks like pose estimation, tracking and identifying individuals. Using the latent space features, we are able to build more effective supervised learning frameworks that require 50 times fewer training samples than prior work while maintaining accuracy.
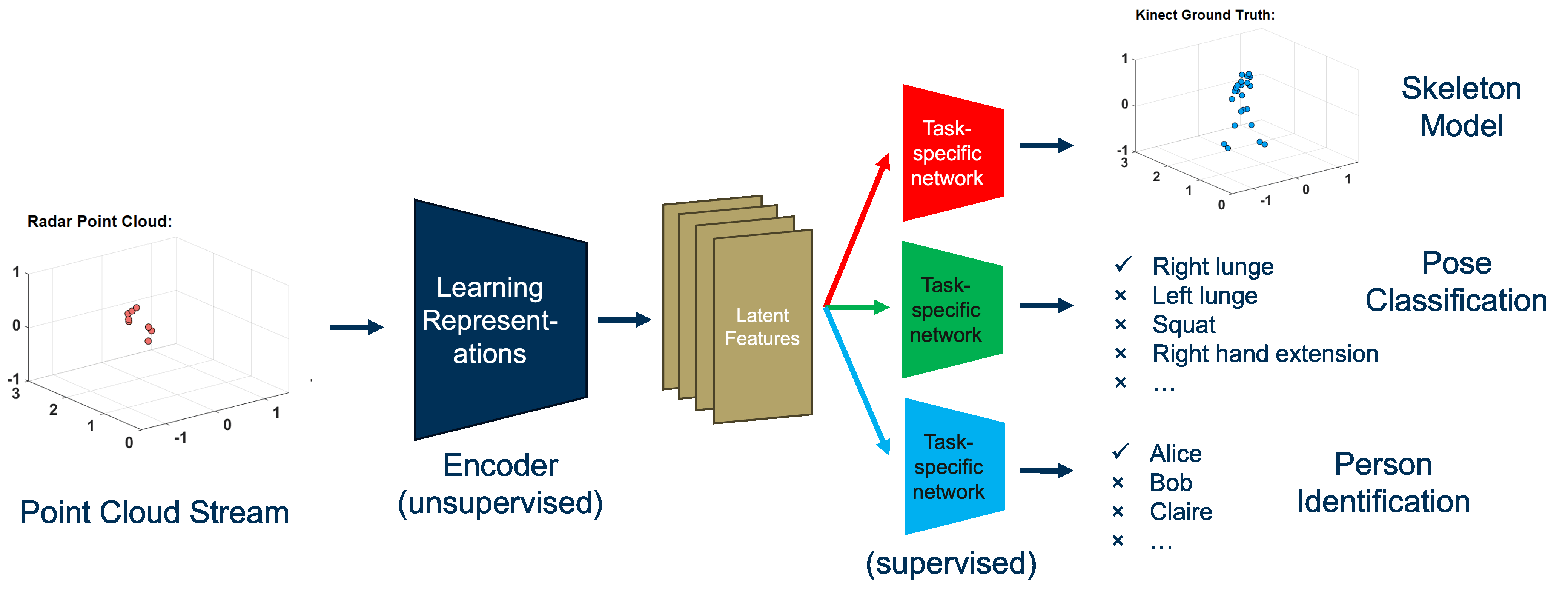
The first step in the overall approach is to learn the mapping to low-dimensional latent features of the mmWave point cloud. To learn this mapping, we draw inspiration from PointNet (Qi et al., 2017a) which is an autoencoder. Additionally, the autoencoder must be built in a way which is invariant to permutations of the point cloud. This condition is necessary because we are trying to understand the motion of humans, and the individuals could be facing any direction, not just the mmWave radar head-on. The next step is to choose a supervised task. There are several open problems in this domain which span reconstructing a skeleton model, classifying different poses, identifying people, etc. We pick the task of reconstructing a skeleton model primarily because of the availability of labelled data.
Download report, presentation here.